决策树算法的执行过程分析
Poblog 05月07日 2018
1.运用决策树进行新加入数据分类的整体流程
已知条件:一组包含了若干特征值和对应的最终分类的数据
输入:和上面特征值数据一一对应的新的特征值信息
执行算法后得到:输入的这组特征值对应的分类
2.信息熵:数据越无序包含的信息越多,对应的信息熵也越大
信息熵计算公式: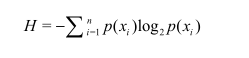 信息增益:由于某个条件的加入使得信息熵减小,该条件带来的信息增益就是这个减小的值
信息增益:由于某个条件的加入使得信息熵减小,该条件带来的信息增益就是这个减小的值
信息增益计算公式:该条件的信息增益=原信息熵-该条件下的信息熵
决策树算法运用信息增益来选择最好的分类划分顺序,比如两个特征A和B,因为A的信息增益更大则先用特征A划分
3.构建决策树的算法执行流程
例子:根据两个海洋生物特征判断该生物是否是鱼类,特征如下

('no surfacing')-不浮出水面是否可以生存
('flippers')-是否有脚蹼
上面的表格数据转换成矩阵表示为:
dataSet=[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
两个特征值的标签为
labels=['no surfacing', 'flippers']
构建决策树算法的执行需要先构建相应的梯子
梯子1-计算香农熵(数据集划分时需要用到)
可能的输入情况:
(1.)整个dataSet --得到整个dataSet的香农熵
(2.)在某个条件下dataSet的香农熵,比如no surfacing=1时
这时输入的dataSet为[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no']]
以完整dataSet为例子的计算过程数据流分析:
dataSet=[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
依次遍历矩阵每一行统计类别数,单步流程如下
取到第一行
[1, 1, 'yes']
取到这行标签
'yes'
统计标签为yes的条数
{'yes': 1}
遍历完毕得到统计为
{'yes': 2, 'no': 3}
根据上面的公式遍历统计结果计算香农熵
根据累加公式计算香农熵
shannonEnt-=prob*log(prob,2) #计算香农熵
中间概率和中间值记录如下
prob:'yes' => 0.4
shannonEnt=0.5287712379549449
prob:'no' => 0.6
shannonEnt=0.9709505944546686
最终得到dataSet对应的香农熵为0.9709505944546686
梯子2-划分数据集
输入 (1.)要划分的dataSet (2.)划分第几个特征 (3.) 筛选特征的数据值
输出 划分之后得到的数据集
例子如下:
dataSet=[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
axis=0 第1个特征
value=0 选择第一个特征的值为0的条目
依次遍历筛选
符合的有
[0, 1, 'no'] ---> [1, 'no']
[0, 1, 'no'] ---> [1, 'no']
刷选完毕得到划分之后得到的数据集为
[[1, 'no'], [1, 'no']]
梯子3-整合上面的两个梯子来选择最好的数据集划分
输入:用来选择的dataSet
输出:dataSet中信息增益最大的是哪个特征(决定先用哪个特征来决策)
数据流如下:
dataSet=[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
计算dataSet的香农熵为0.9709505944546686
依次遍历dataSet的所有特征
遍历每个特征的所有的可能取值,对于第1个特征提取过程为
[1, 1, 1, 0, 0] -->{0, 1}
然后依次对每个特征值划分数据集
如第一个特征会划分两次分别是(dataSet,0,0)和(dataSet,0,1)
再根据每个划分条目数占整个条目的比例计算得到这个特征的信息增益
如通过(dataSet,0,0)划分得到[[1, 'no'], [1, 'no']] 2条 dataSet一共有5条 该划分的香农熵为H1
通过(dataSet,0,1)划分得到[...] 3条 dataSet一共有5条 该划分的香农熵为H2
第一个特征的信息增益为 dataSet香农熵-(2/5 * H1+3/5 * H2)
通过上面的计算比较信息增益最大的特征进行划分即为最好的数据集划分
梯子4-最终决策树的创建
输入:dataSet,labels
输出:创建好的决策树结构
流程如下:
dataSet=[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
labels=['no surfacing', 'flippers']
labels和dataSet的特征依次对应
使用dataSet得到最好的划分
利用上面的梯子计算得到是第1个特征 'no surfacing'
当前得到决策树如下
{'no surfacing': {}}
运用迭代很容易得到最终决策树为
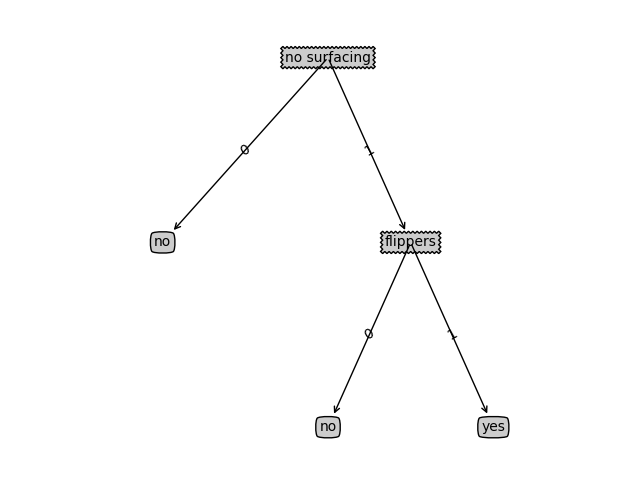
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
需要注意的是迭代结束返回叶子节点的条件是
1.划分结果的所有分类是一样的,这种直接返回分类作为叶子节点
2.所有特征使用完毕,这种情况返回占多数的分类作为叶子节点
决策树画图得到的图形如下:
4.运行构建的决策树对新输入进行分类
输入:(1).决策树 (2).labels (3).一一对应的一组特征值
举例:
决策树:{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
labels=['no surfacing', 'flippers']
一组特征值=[1, 1]
沿着决策树找到叶子节点即可
如本例子的最终分类为'yes'
参考资源git地址如下:


